この度、住んでいる浜田市の若者会議の委員に選任されました。
やることとしては、委員各々が持つスキルとかを使って若者が過ごしやすい街づくりを進める感じです
より詳しいことは下記のPDFを読んでいただければわかります。
https://www.city.hamada.shimane.jp/www/contents/1446178852885/files/senryakupu.pdf
今後に関しては僕の守備範囲であるIT系の話とかしつつ、住みやすい街づくりに協力できればと思います
この度、住んでいる浜田市の若者会議の委員に選任されました。
やることとしては、委員各々が持つスキルとかを使って若者が過ごしやすい街づくりを進める感じです
より詳しいことは下記のPDFを読んでいただければわかります。
https://www.city.hamada.shimane.jp/www/contents/1446178852885/files/senryakupu.pdf
今後に関しては僕の守備範囲であるIT系の話とかしつつ、住みやすい街づくりに協力できればと思います
仕事の関係で一括でBacklogに複数のチケットを登録する必要があり、作成したものになります。 手作業なんて面倒くさいことしたくない人は是非使ってみてください。
使い方は簡単。
上記のコードをクローンした後、必要なAPIキーなどを.envに追加
SPACE_ID=<スペースID> API_KEY=<APIキー> PROJECT_ID=<プロジェクトID> ISSUE_TYPE_ID=<チケットのタイプ> PRIORITY_ID=<優先度>
その後、tickets.mdをクローンしたディレクトリ内に以下のように作成。
### ○○の修正対応 ○○は××だったのでそのように修正 TICKET_END ### △△の修正対応 △△は××だったのでそのように修正 TICKET_END
TICKET_ENDで各チケット毎に区切るようにしています。
あとはbundle installなどをした後にbundle exec ruby main.rbを実行するだけです。
bundle exec ruby main.rb
Hamada.rbとかCoderDojo浜田とかでアレコレ作ったりしてたのがきっかけで知り合った方から「授業(という体のインタビュー)をしてみませんか?」とお誘い頂いたのがきっかけですね。
で、話を聞いてみると浜田高校では以下のような取り組みをしていて「地域の頑張っている人に話を聞く」ということをしているとのこと。
面白い取り組みだったのと、こういう地方だとプログラマーに直接話を聞く機会とかもないだろうしと思ったので、快諾。
で、今日色々と仕事の話とかHamada.rbとかでやってるアプリ開発の話とか話してきました。
Hamada.rbでやってるアプリ開発(避難先のGoogleMapアプリ)とかの話がメインで、それ以外に実際にプログラマーってどんな仕事かとかを話してきました。
アプリ開発の文脈で、ノーコードツールとかの話もしましたね。
意外と食いつきが良かったのは、実際に作ったアプリを見せた時ですね。
「どれぐらいでつくれるのか?」とか質問が来てました。
あと仕事の話も意外と興味をもって貰えたようでした。
浜田市とかだとプログラマーとして仕事している人はかなり少ないので、珍しかったのもありそう。
あと、リモートで働いているというのも面白かったみたいです。
こういうのがきっかけでプログラミングに興味を持って貰える可能性はあるので、今後も参加できるようなら参加していきたいですねー。
あとは実際に高校生たちが考えたアプリとかを作ってみるのも面白いかもと思ったりしましたねー。
この記事は、仕事で触ることになったGo製Zoomライブラリを触った時の備忘録です。
実際に試せるサンプルコードもありますので、気になった人は以下のリポジトリをクローンして試してみてください。
まず、Zoomの開発者登録とか済ませてAPIキーなどを取得します。
APIキー取得後、.envに取得したAPIキーとシークレットキー、そしてZoomのMTGを作成するために必要なホストのユーザーIDを追加します。
ZOOM_API_KEY=<APIキー> ZOOM_API_SECRET=<シークレットキー> USER_ID=<ユーザーID>
次に、必要なライブラリを落としてきます。
go get -u github.com/himalayan-institute/zoom-lib-golang github.com/joho/godotenv
最後に、main.goを以下のように作成します。
package main import ( "log" "os" "github.com/joho/godotenv" "github.com/himalayan-institute/zoom-lib-golang" ) func main() { err := godotenv.Load() if err != nil { log.Fatalf("Error loading .env file") } var ( apiKey = os.Getenv("ZOOM_API_KEY") apiSecret = os.Getenv("ZOOM_API_SECRET") userID = os.Getenv("USER_ID") ) zoom.APIKey = apiKey zoom.APISecret = apiSecret var createMeetingOpts zoom.CreateMeetingOptions createMeetingOpts.HostID = userID meeting, err := zoom.CreateMeeting(createMeetingOpts) if err != nil { log.Printf("Got err: %+v\n", err) } log.Printf("Get Meeting Info: %+v\n", meeting) }
あとはgo run main.goを実行するとZoomのMTGが作成されます。
go run main.go
仕事でも使っているライブラリなんですが、結構簡単にMTGが作成できるので良い感じです。 今後GoでZoomのAPIを使う必要があるかたは是非触ってみて欲しいですね。
この記事は、仕事で必要なライブラリにパッチを投げてそれがマージされた時の備忘録です。 今後もパッチを投げる可能性があるのでメモ書きとしてまとめている感じです。
最近、仕事ではもっぱらGoを書いているんですが、ライブラリにパッチを投げるとかそういうことはなく平穏な日々を過ごしてました。 が、数か月前から仕事で大き目な機能改修があり、「さすがにこれは使ってるライブラリを改修しなければならないな」という事態が起きたんですよね……。
まあ、こういう時によくあるのは「Forkしてそれを改修する」か「改修したパッチを投げてマージされるようにする」のどちらかだと思います。
で、今回は後者のパターンで行くことにしたんですね。
理由としては二つありまして
こんな感じですね。
Forkするのは最初は良いんですが、だんだんメンテナンスするのが辛くなってくるのでやりたくなかったんですよねぇ……。 それに、Goのライブラリにパッチ投げたこともなかったので「いい機会だしやってみるか」となり、パッチを書くことにしました。
実際に作ったPRとしては以下です。
Zoomではグループというものを設定することができ、グループ単位でMTGとかの設定をすることができるようになっています。
今までは手動でグループにユーザーを追加していたんですが、ユーザー数が多くなると面倒くさかったりします。 で、今回の機能改修ではその辺を自動的にできるようにしたかったので上記のPRを投げた感じですね。
やってることとしては、group_member_post.goというファイルを追加して、ついでにサンプルコードを追加しました。
実際に追加しているコードとしては以下通りです。
package zoom import "fmt" // AddMenbersPath - v2 path for add group members const AddMenbersPath = "/groups/%s/members" // AddMemberOptions are details about add group members type AddMemberOptions struct { GroupID string `json:"-"` Members []Member `json:"members"` } // Member represents an group member type Member struct { ID string `json:"id"` Email string `json:"email"` } // ResopnseAddGroupMembers represents response for added member to group type ResopnseAddGroupMembers struct { // IDs has comma-delimited, like 'xxxxxxxxxx,xxxxxxxxxx' IDs string `json:"ids"` AddedAt string `json:"added_at"` } // AddMembers calls POST /groups/{groupId}/members func AddMembers(opts AddMemberOptions) (ResopnseAddGroupMembers, error) { return defaultClient.AddMembers(opts) } // AddMembers calls POST /groups/{groupId}/members // https://marketplace.zoom.us/docs/api-reference/zoom-api/groups/groupmemberscreate func (c *Client) AddMembers(opts AddMemberOptions) (ResopnseAddGroupMembers, error) { var ret = ResopnseAddGroupMembers{} return ret, c.requestV2(requestV2Opts{ Method: Post, Path: fmt.Sprintf(AddMenbersPath, opts.GroupID), DataParameters: &opts, Ret: &ret, }) }
基本的に他の部分と同じような実装にして、かつZoomのAPIに書かれているパラメータを構造体として追加しています。
あと実際に使う場合のサンプルコードは以下の通りです。
package main import ( "log" "os" "github.com/himalayan-institute/zoom-lib-golang" ) func main() { var ( apiKey = os.Getenv("ZOOM_API_KEY") apiSecret = os.Getenv("ZOOM_API_SECRET") userID = os.Getenv("USER_ID") groupID = os.Getenv("GROUP_ID") ) zoom.APIKey = apiKey zoom.APISecret = apiSecret addMemberopts := zoom.AddMemberOptions{ GroupID: groupID, Members: []zoom.Member{ { ID: userID, }, }, } member, err := zoom.AddMembers(addMemberopts) if err != nil { log.Printf("Got add members: %+v\n", err) } log.Printf("Resopnse add members: %+v\n", member) }
サンプルの追加と実装の追加はそんなに難しくはなかったですね(まあ、実際には色々フィードバックをもらったので直してたりしましたが……)
あと、CIの設定を弄る必要があるのに早い段階で気づけなかったのはよくなかったなぁと……。
とりあえず、仕事の改修にも間に合って無事マージされたので良かったです。 とはいえ、まだ改修しなきゃいけないとことかあるので必要に応じて今後もパッチを投げていきたいですねー。
以前書いた以下の記事の内容をそのままterraformでできるようにしてみました。
またついでにSlackなどに投げれるように文字起こししたファイルを受け取るLambda関数も追加してみました。
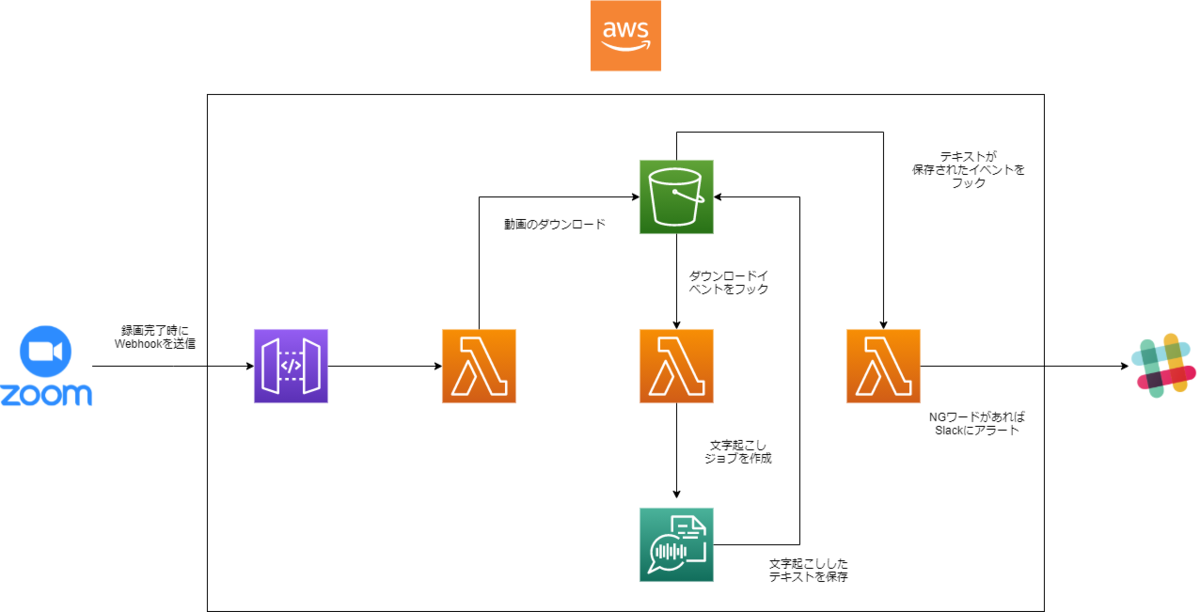
こんな感じでZoomで録画されたデータをWebhookで受け取り、Lambdaなどでよしなにする感じです。 今回のterraformに落とし込んだところでは実装していませんが、最後のSlackの部分は録画データ内に何かしらのNGワードがある場合にアラートが飛ばす感じですね。
まず必要な環境変数をターミナルにexportしてください。
export AWS_ACCESS_KEY_ID=xxxxxxxxxxx export AWS_SECRET_ACCESS_KEY=xxxxxxxxx export AWS_REGION=xxxxxxxxx export TF_VAR_access_key=xxxxxxxxx export TF_VAR_secret_key=xxxxxxxxx export TF_VAR_role_arn=xxxxxxxxxx
その後、terraform initで初期化します。
terraform init
初期化が完了したらterraform planで差分を確認します。
terraform plan
確認時に文法エラーなど無ければ、terraform applyでデプロイできます。
terraform apply
この記事は先日書いたAWSとRubyを使って動画ファイルの自動文字起こしを試してみた時の続きです。
今回は実際にZoomの録画データを自動的に文字起こしできるようにしてみました。
とりあえず、手順をまとめただけなのでいくつか設定が抜けている可能性があります。 悪しからずご了承ください。
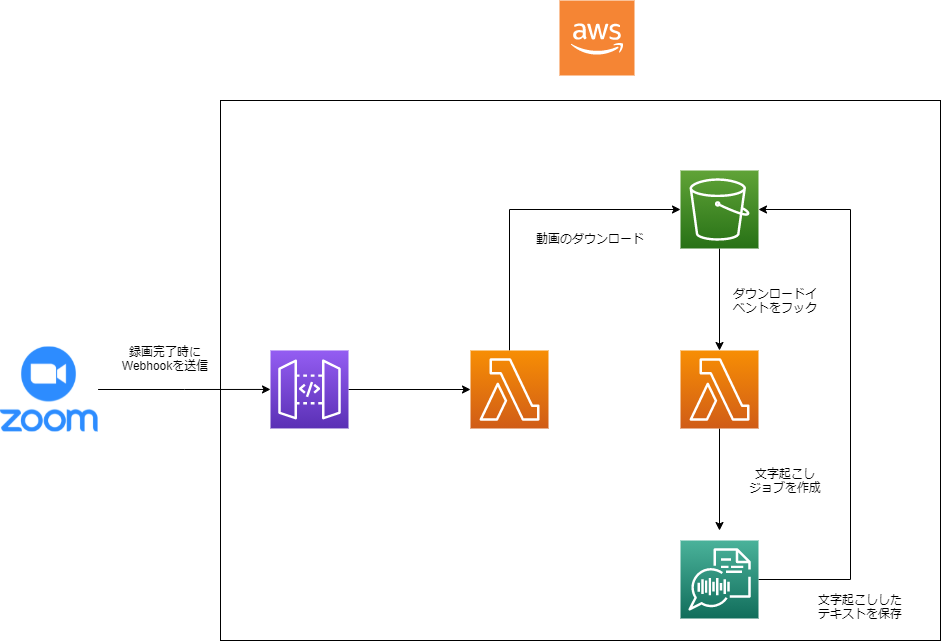
Zoomで録画ファイルが作成されたときのWebhookをAPI Gatewayで受け取り、LambdaでS3へとダウンロードしています。 ダウンロードされたタイミングでTranscribeの文字起こしジョブをLambdaで実行し、S3へ文字起こししたデータを保存しています。
まずは、S3に動画データと文字起こししたテキストを保存するためのバケットを作成します。
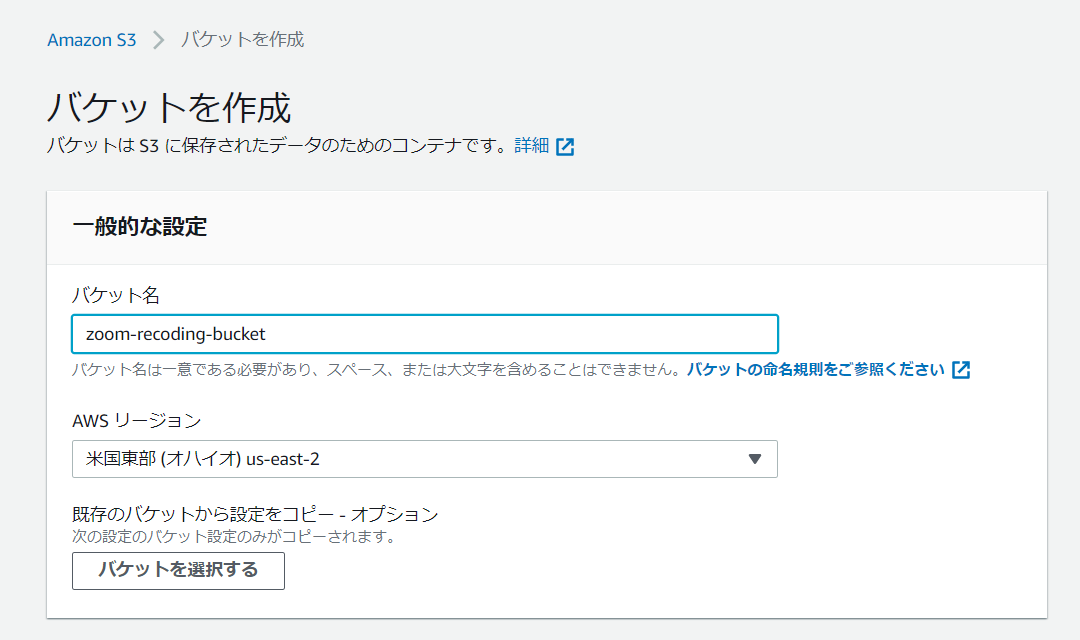
この時注意が必要なのはリージョンをどこにするかです。 ただし、Amazon Transcribeが使えるリージョンと同じリージョンを設定する必要があります。
ちなみに、Amazon Transcribeが使えるリージョンは以下記事によると東京のほかオハイオやオレゴンなどがあるようです。
今回はオハイオを使っていきます。
他に設定する項目もないので、このまま「バケットを作成」をクリックします。
バケット作成後、以下のようにrecordingとtextディレクトリを作成します。
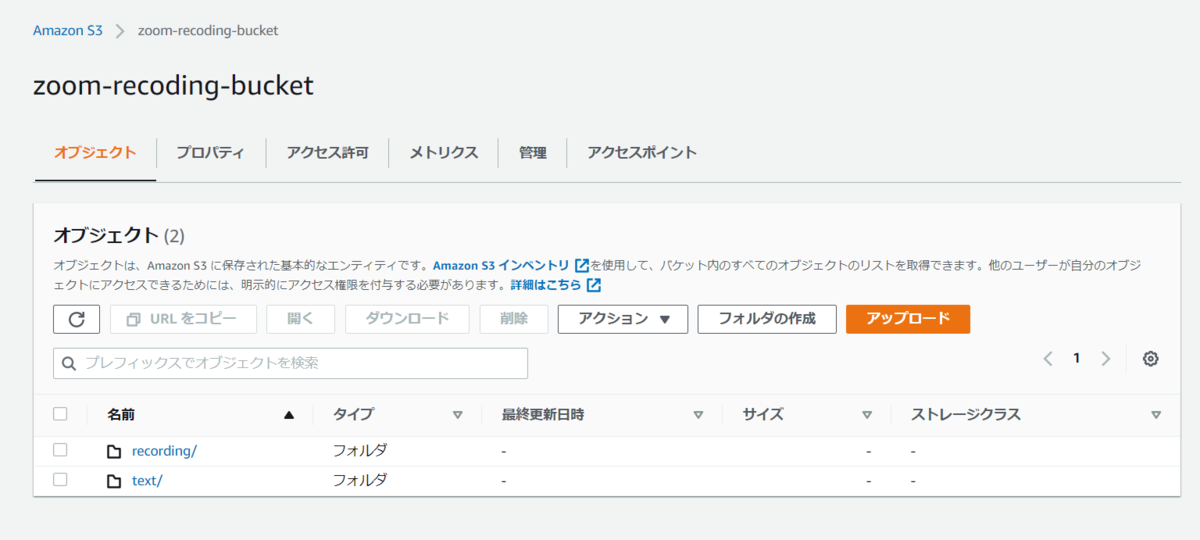
ディレクトリの作成が完了したら、S3でするべき作業は完了です。
次に、AWS LambdaでS3に録画データを保存できるようにしていきます。
まずは、Lambdaの関数を以下のように作成します。
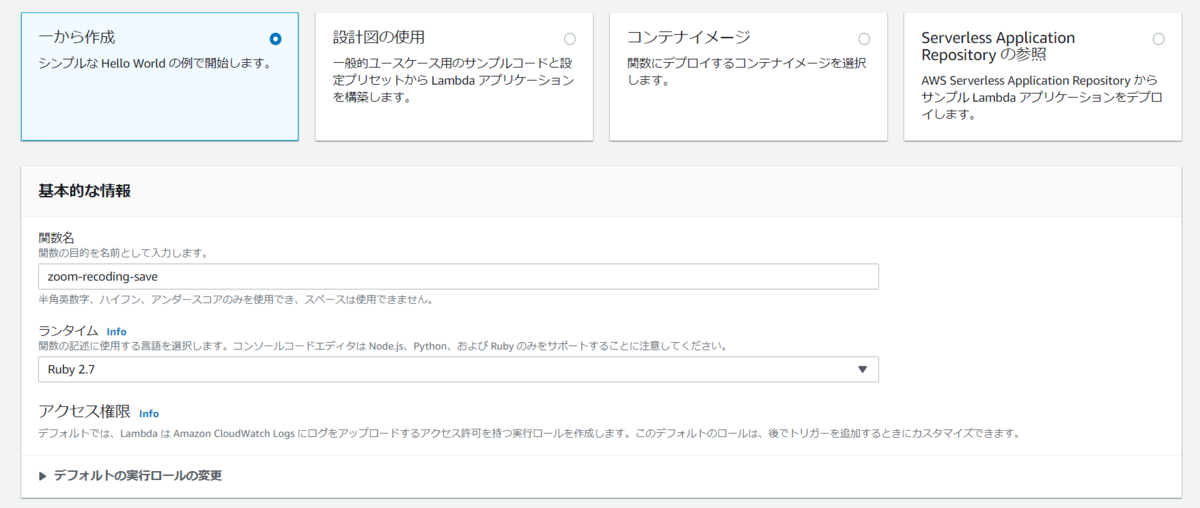
「デフォルトの実行ロールの変更」は最初から設定されている「基本的な Lambda アクセス権限で新しいロールを作成」でOKです。
最後に「関数の作成」をクリックしてLambdaの関数を作成します。
関数作成後、Zoomの録画データを保存するためのコードをRubyで書いていきます。
require 'json' require 'logger' require 'aws-sdk-s3' require 'open-uri' require 'net/http' def lambda_handler(event:, context:) logger = Logger.new($stdout) logger.info(event) body = JSON.parse(event["body"]) logger.info(body) logger.info("Get Zoom Recording file download path") region = 'us-east-2' bucket_name = "zoom-recoding-bucket" s3_client = Aws::S3::Client.new(region: region) recording_files = body["payload"]["object"]["recording_files"] meeting_id = body["payload"]["object"]["id"] token = body["download_token"] path = recording_files[0]["download_url"] download_path = "#{path}?access_token=#{token}" object_key = "#{meeting_id}.mp4" logger.info(download_path) logger.info(token) URI.open(download_path) do |file| s3_client.put_object({ :bucket => bucket_name, :key => "recording/#{object_key}", :content_type => "movie/mp4", :body => file.read }) end end
Zoomの録画データをダウンロードする際には、ダウンロード用のトークンとURLを組み合わせる必要があります。 そのため下記のように新しい文字列を生成しています。
token = body["download_token"] path = recording_files[0]["download_url"] download_path = "#{path}?access_token=#{token}"
また、Lambdaの/tmpでは最大512MBしかファイルを保存できないので大規模な録画データの対応も考え、URI.openで受け取ったデータをそのままS3へと渡しています。
Zoomで保存されている録画データはMP4形式のファイルとなっていますので、MP4でS3に保存するよう指定しています。
URI.open(download_path) do |file| s3_client.put_object({ :bucket => bucket_name, :key => "recording/#{object_key}", :content_type => "movie/mp4", :body => file.read }) end
最後に、Lambdaで使用するメモリとタイムアウトまでの時間を変更します。
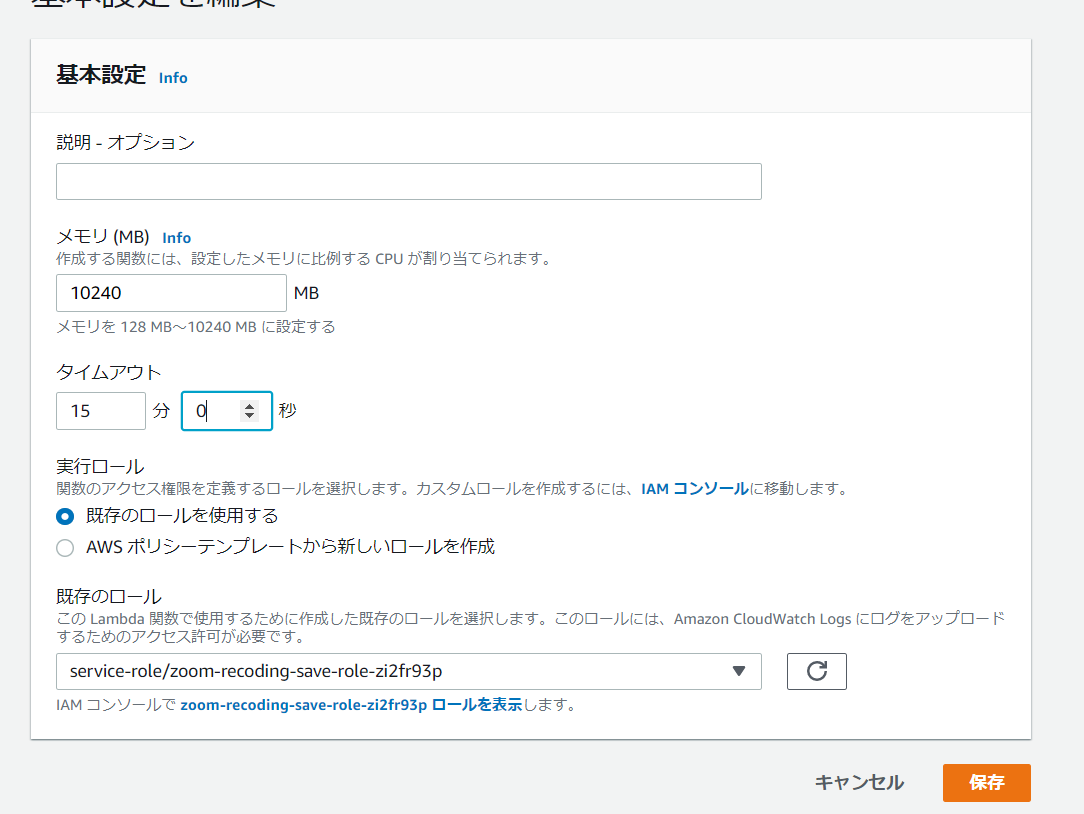
これでLambdaで録画データを保存する処理は完成です。
AWS IAMの管理画面を開き、Lambdaで関数を作成するときに生成したロールを選択します。
ロールにS3への書き込み権限を渡したいので「ポリシーをアタッチします」をクリックし、S3への書き込み権限を付与します。
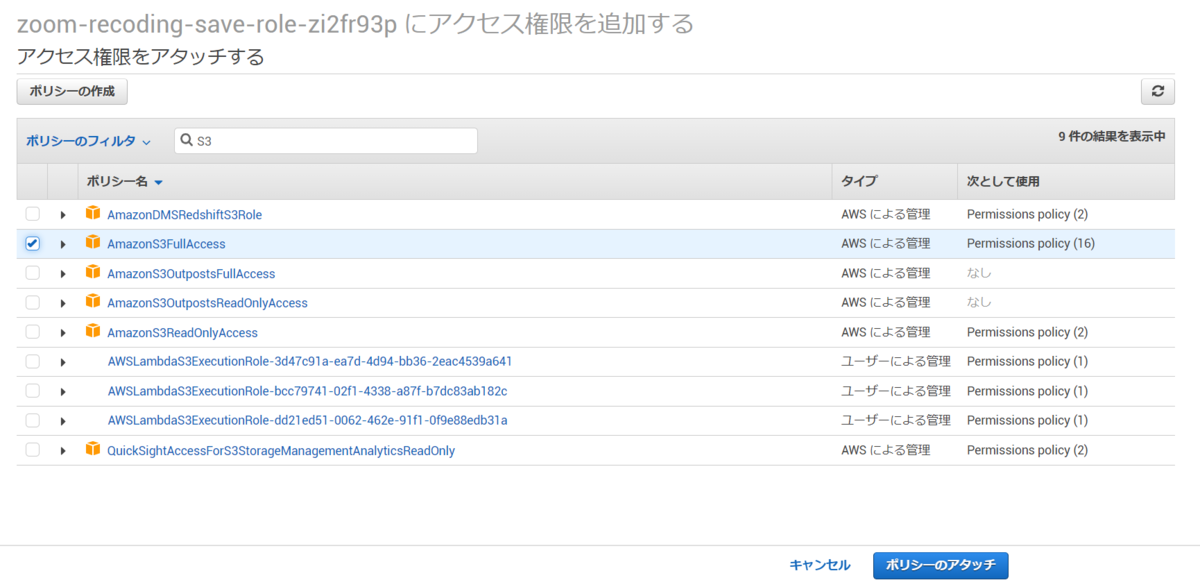
今回は動作していることが確認できればいいので、FullAccessを選択しています。 本来であれば、書き込みのみの権限にした方がいいと思います。
追加するポリシーをチェックした後、「ポリシーのアタッチ」をクリックし、権限を付与します。
次にAmazon API GatewayでWebhookを受け取る窓口を作成します。
API Gatewayの管理画面に移動し、「APIを作成」をクリックします。 以下のような画面が表示されます。
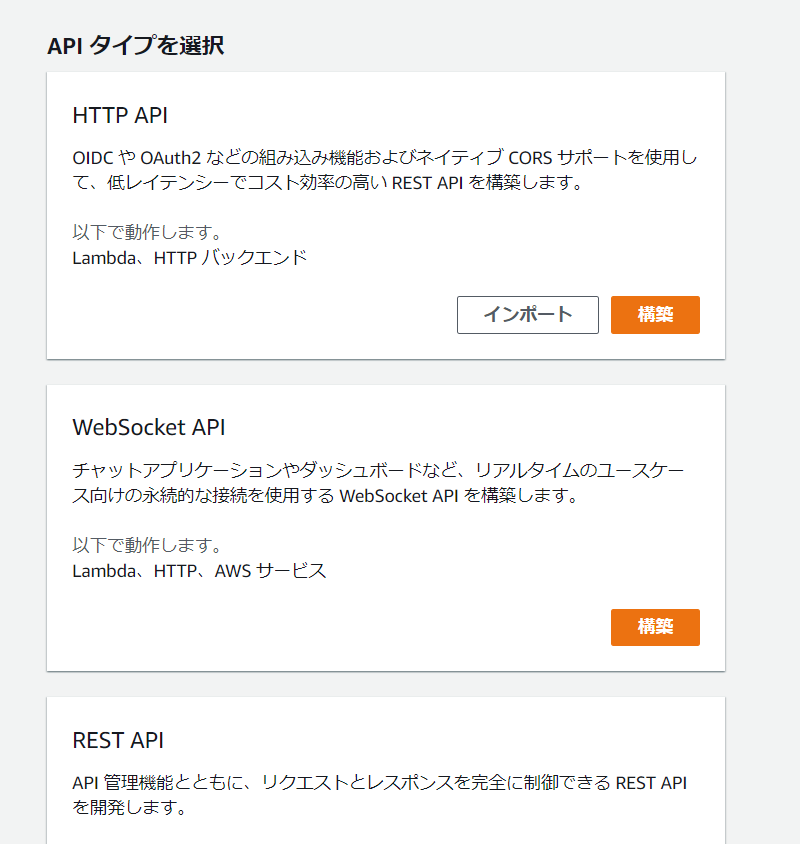
ここでは、「HTTP API」を使用します。「HTTP API」の枠内にある「構築」をクリックします。
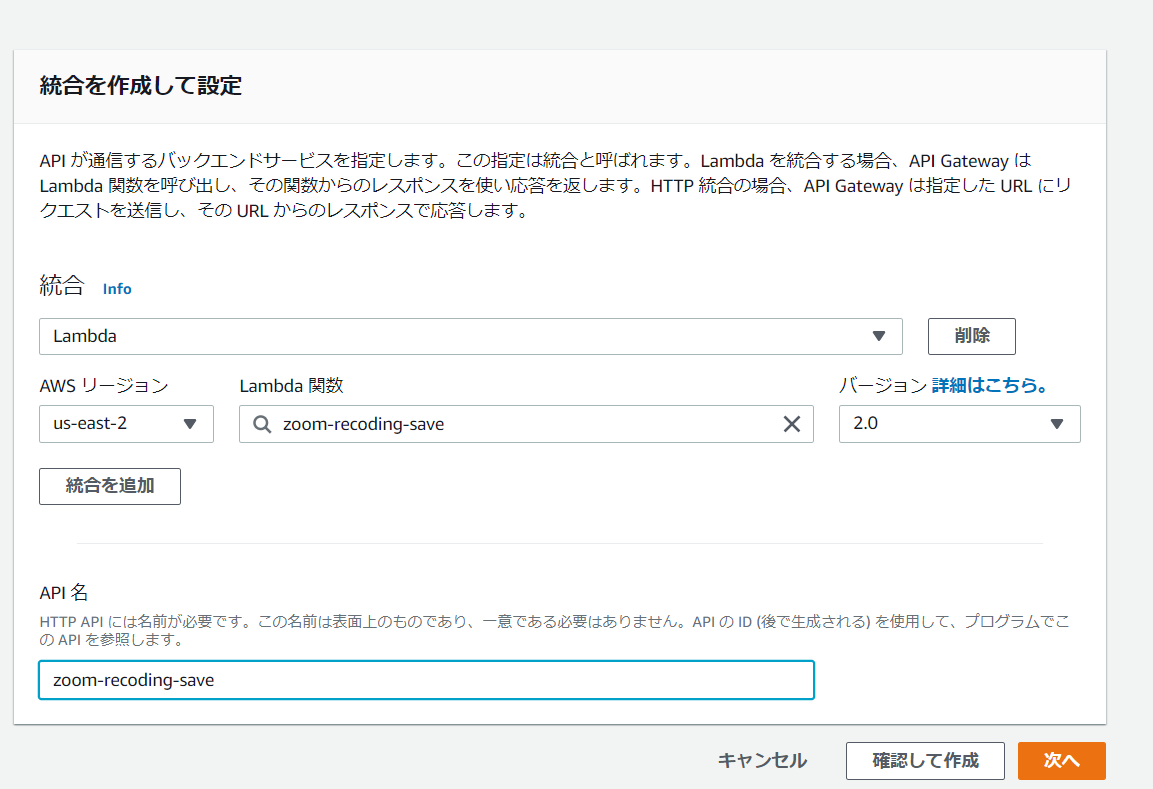
クリック後、上記の画面に遷移するので必要な設定を埋めていきます。
まずは「統合を追加」をクリックし、API Gatewayが使用するバックエンドサービスを選択します。 今回は、先ほど作成したLambda関数を指定しています。
また「API名」も入力する必要があるので任意の名前を入力してください。
諸々の設定を入力後、「確認して作成」をクリックします。
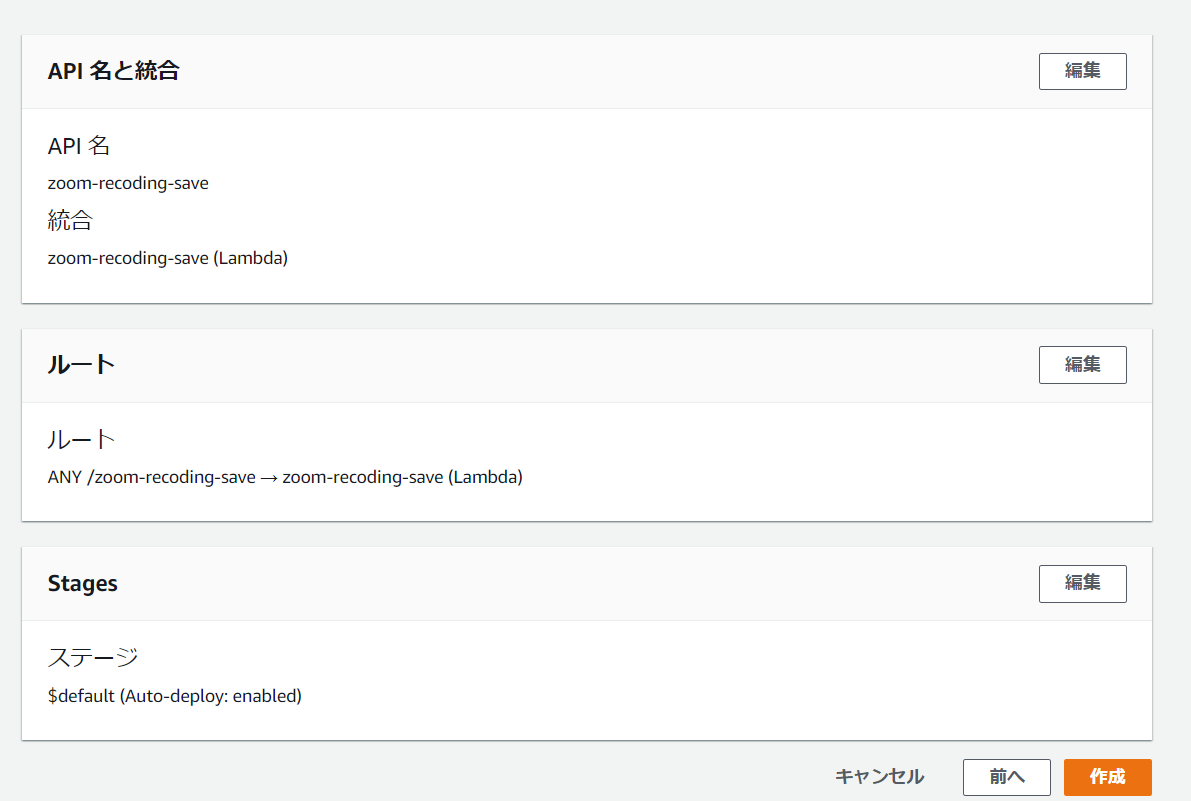
上記の画面に遷移します。 設定内容が正しいか確認したうえで「作成」をクリックします。
これでWebhookを受け取る窓口が作成できました。
Zoomの開発者としてアカウントを設定後、https://marketplace.zoom.us/develop/createにアクセスします。
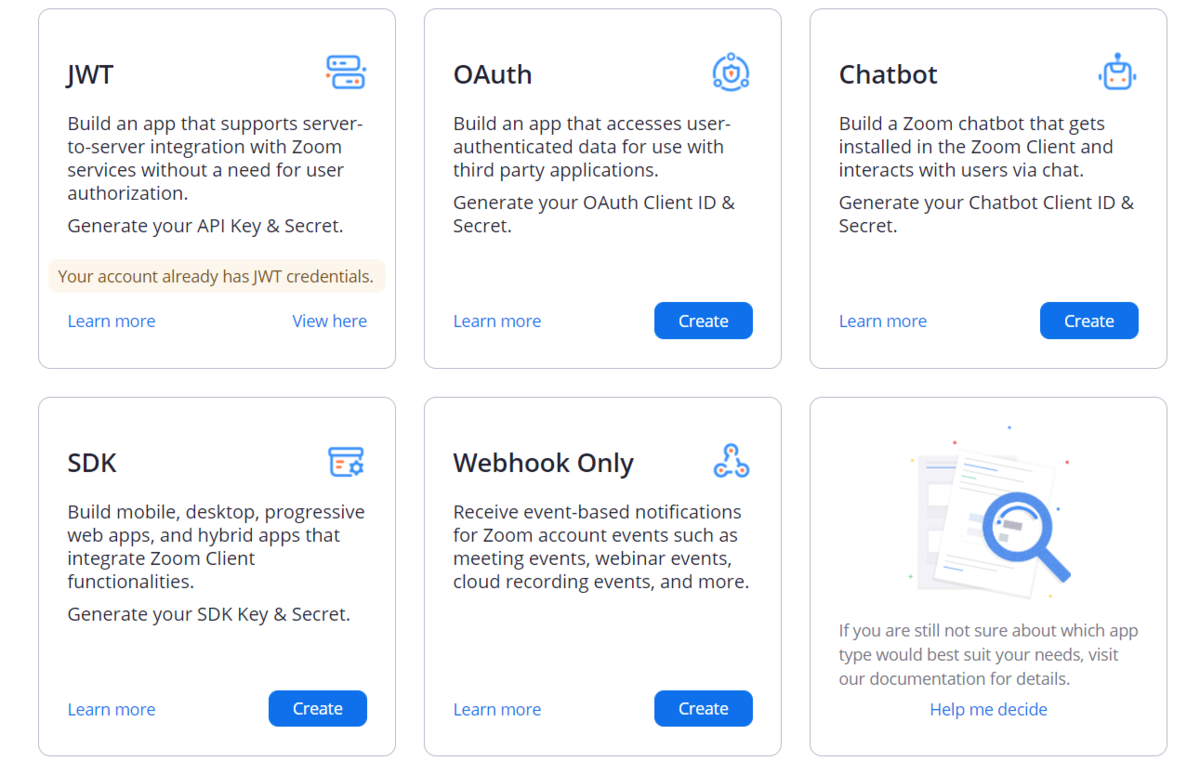
今回はWebhookが使えればいいので「Webhook Only」を選択し、新しくアプリを作成します。
アプリ作成後、以下の画面に遷移しますので赤枠の部分を埋めています。
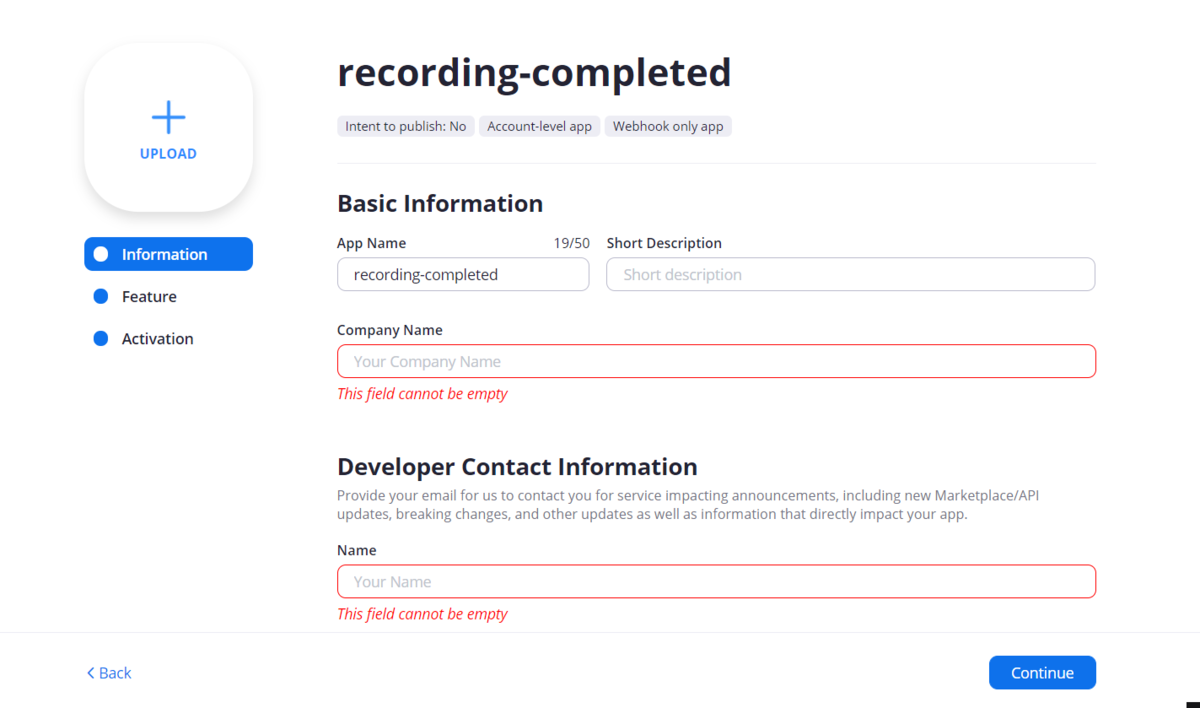
埋め終わったらページ下部の「Continue」をクリックします。
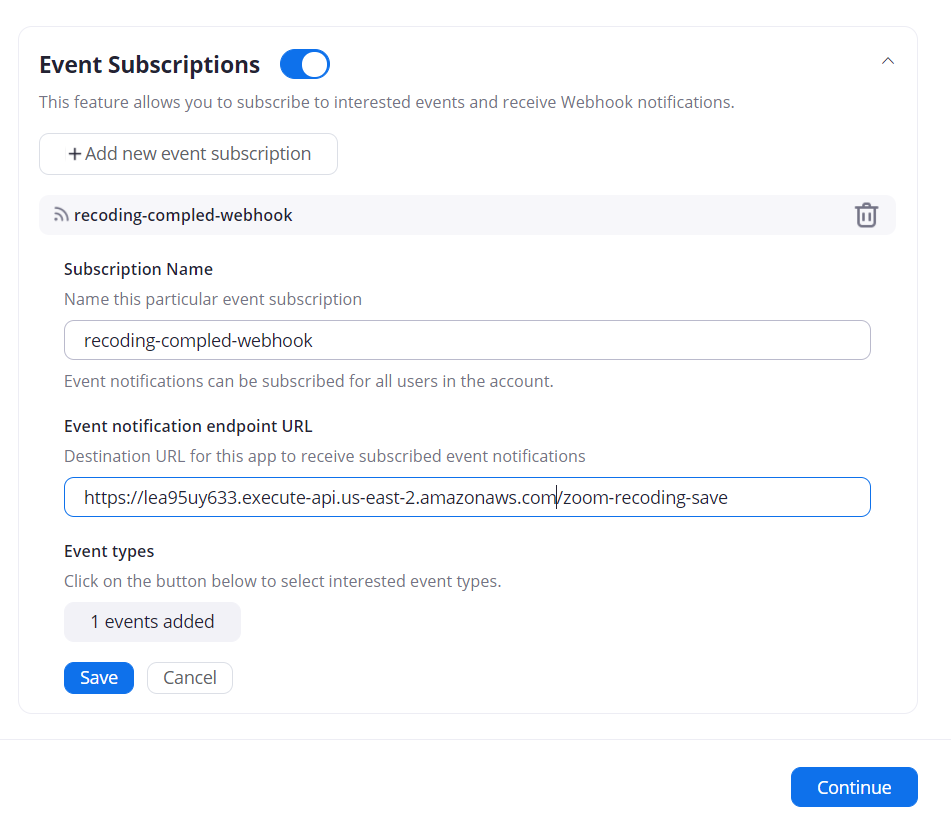
クリック後、上記の画面に遷移します。
「Event Subscriptions」を有効にし、「Subscription Name」に適当な名前を入力し、「Event notification endpoint URL」には先ほど作成したAPI Gatwayのルートを記入します。 また「Event types」には「All Recording have completed」を選択します。
最後に「Continue」をクリックし、アプリを作成します。
これでZoom側での設定は完了です。
最後にS3にファイルをアップロードされたタイミングで文字起こしをするジョブをTranscribeへと投げる処理を作成していきます。
ここでも再度Lambdaで関数を作成します。
関数名は任意の名前を付けてください。ランタイムは先ほどと同じようにRuby 2.7を使用します。
関数作成後、以下のようにジョブを投げるコードを書きましょう。
require 'json' require 'aws-sdk-transcribeservice' require 'logger' def lambda_handler(event:, context:) logger = Logger.new($stdout) logger.info("Hook Event") logger.info(event) record = event["Records"][0] s3 = record["s3"] region = record["awsRegion"] bucket = s3["bucket"]["name"] object_key = s3["object"]["key"] path = "https://#{bucket}.s3-#{region}.amazonaws.com/#{object_key}" job_name = "TranscriptionJobName_#{object_key.sub(/recording\//, "")}" output_key = object_key.sub(/recording/, "text").sub(/\.mp4/, "") logger.info("S3 info") logger.info(bucket) logger.info(object_key) logger.info(path) client = Aws::TranscribeService::Client.new(region: region) response = client.start_transcription_job({ transcription_job_name: job_name, language_code: "ja-JP", media_format: "mp4", media: { media_file_uri: path }, output_bucket_name: bucket, output_key: "#{output_key}.txt" }) logger.info("TranscriptionJob start #{response.transcription_job.transcription_job_name}") end
あとは、S3の/recordingディレクトリにファイルがアップロードされたタイミングでイベントを実行するように設定します。

「トリガーを追加」をクリックし、以下の画面に移動します。
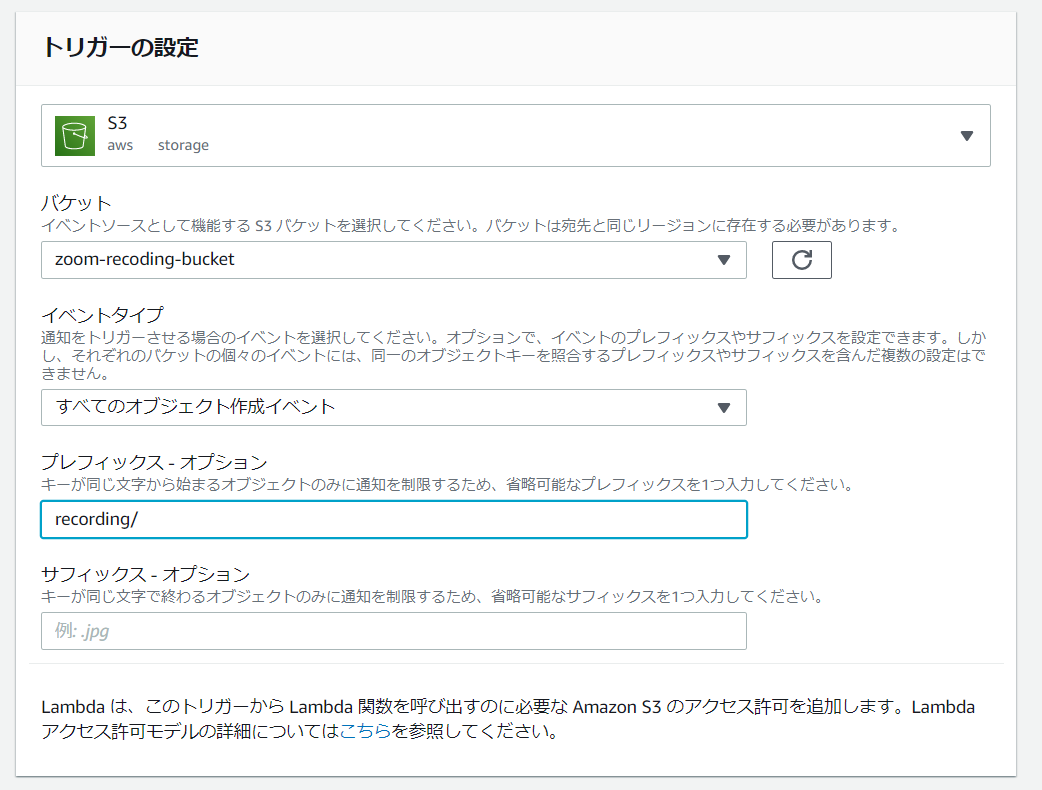
トリガーとなるイベントとバケット名などを入力していきます。
また、プレフィックスにrecording/を指定し、特定のディレクトリだけにアップロードされたイベントをフックしています。
最後に、今回作成した関数のロールに「AmazonTranscribeFullAccess」と「完全に削除」を追加します。 これはS3のファイルを読み取る&Transcribeへジョブを投げる権限を追加する必要があるためです。
最終的に文字起こしで終わっていますが、ここからさらに録画データ内にNGワードがあった場合にSlackに通知するということもできそうです。