はじめに
この記事は先日書いたAWSとRubyを使って動画ファイルの自動文字起こしを試してみた時の続きです。
今回は実際にZoomの録画データを自動的に文字起こしできるようにしてみました。
注意事項
とりあえず、手順をまとめただけなのでいくつか設定が抜けている可能性があります。 悪しからずご了承ください。
実際の構成図
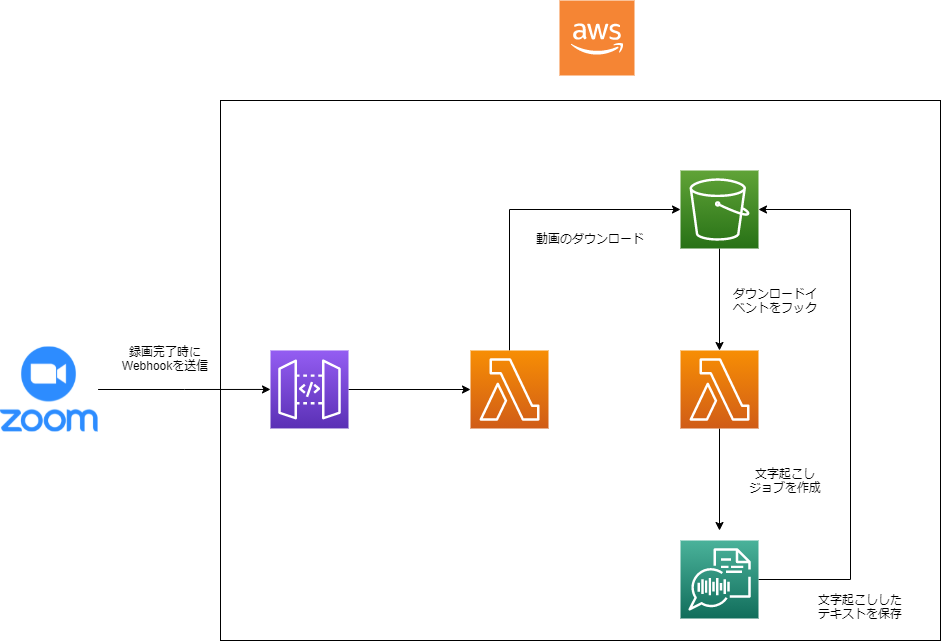
Zoomで録画ファイルが作成されたときのWebhookをAPI Gatewayで受け取り、LambdaでS3へとダウンロードしています。 ダウンロードされたタイミングでTranscribeの文字起こしジョブをLambdaで実行し、S3へ文字起こししたデータを保存しています。
やったこと
S3にバケットを作成
まずは、S3に動画データと文字起こししたテキストを保存するためのバケットを作成します。
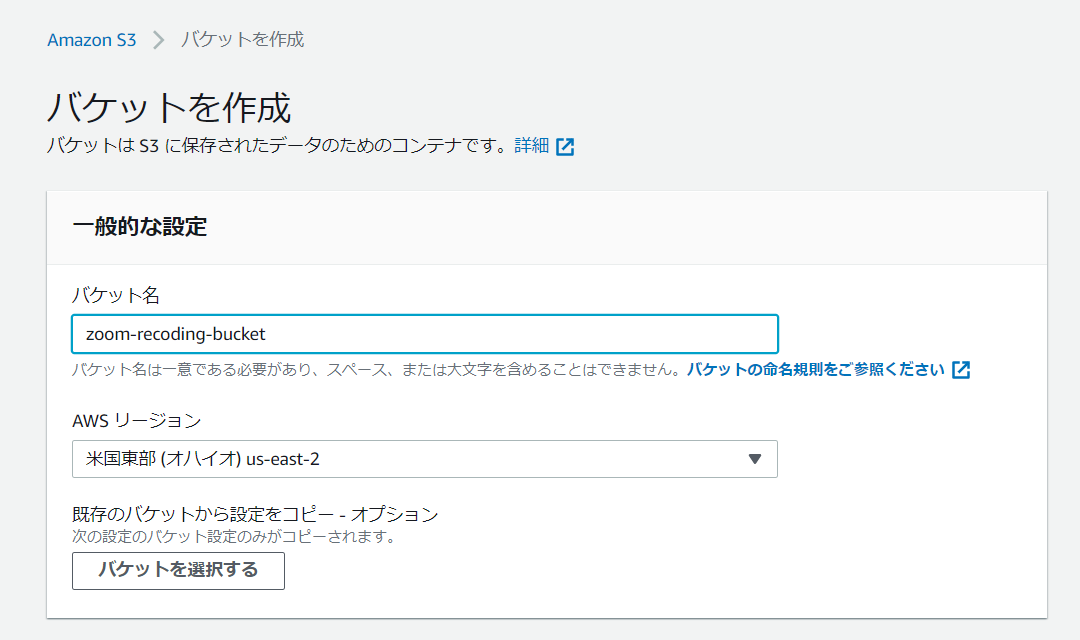
この時注意が必要なのはリージョンをどこにするかです。 ただし、Amazon Transcribeが使えるリージョンと同じリージョンを設定する必要があります。
ちなみに、Amazon Transcribeが使えるリージョンは以下記事によると東京のほかオハイオやオレゴンなどがあるようです。
今回はオハイオを使っていきます。
他に設定する項目もないので、このまま「バケットを作成」をクリックします。
バケット作成後、以下のようにrecordingとtextディレクトリを作成します。
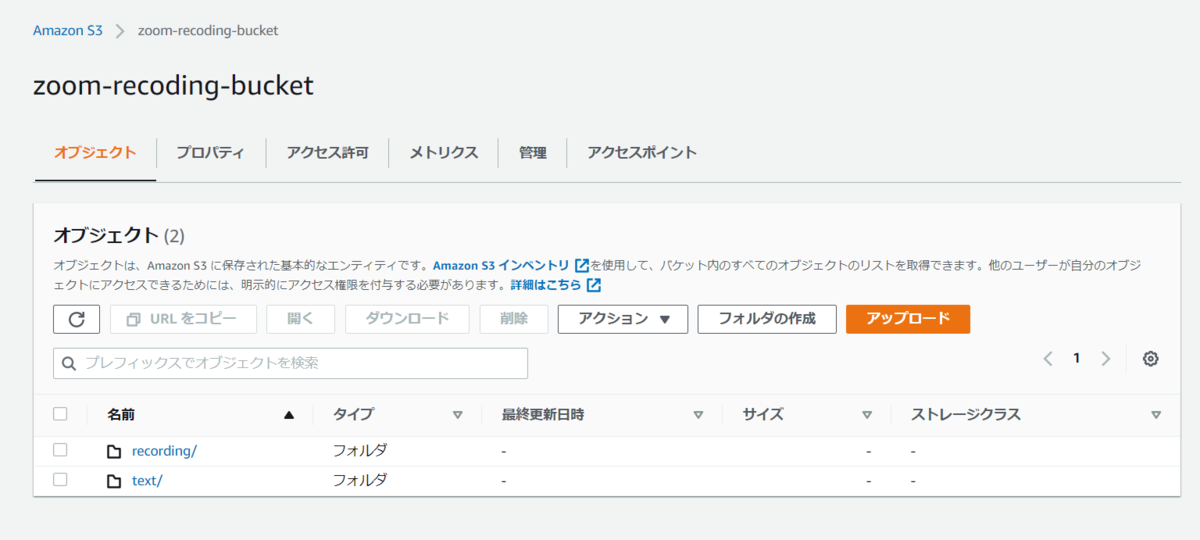
ディレクトリの作成が完了したら、S3でするべき作業は完了です。
LambdaでS3に録画データを保存
次に、AWS LambdaでS3に録画データを保存できるようにしていきます。
関数の作成
まずは、Lambdaの関数を以下のように作成します。
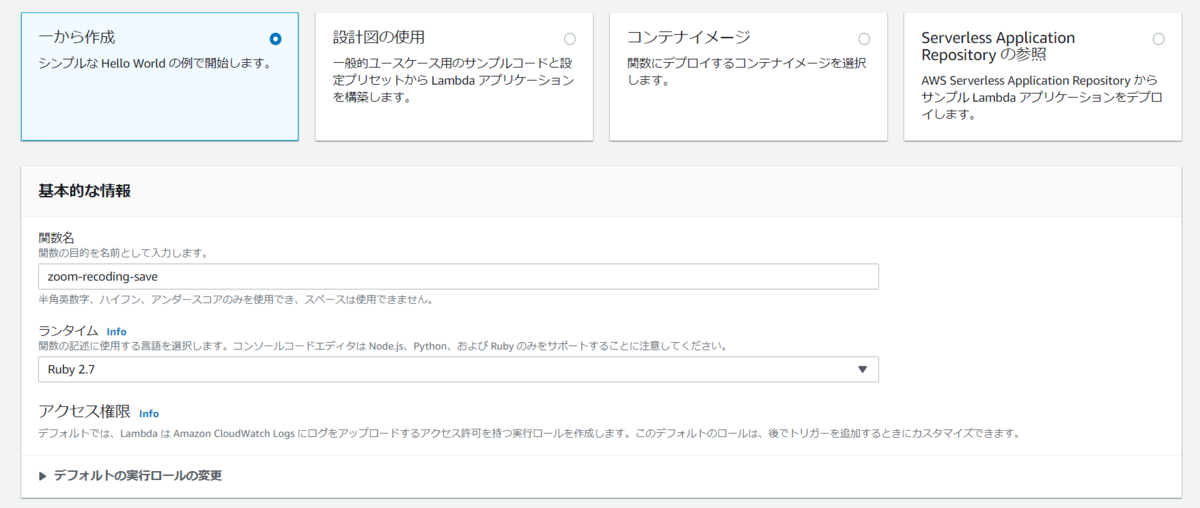
「デフォルトの実行ロールの変更」は最初から設定されている「基本的な Lambda アクセス権限で新しいロールを作成」でOKです。
最後に「関数の作成」をクリックしてLambdaの関数を作成します。
RubyでZoomの録画データを保存するコード
関数作成後、Zoomの録画データを保存するためのコードをRubyで書いていきます。
require 'json' require 'logger' require 'aws-sdk-s3' require 'open-uri' require 'net/http' def lambda_handler(event:, context:) logger = Logger.new($stdout) logger.info(event) body = JSON.parse(event["body"]) logger.info(body) logger.info("Get Zoom Recording file download path") region = 'us-east-2' bucket_name = "zoom-recoding-bucket" s3_client = Aws::S3::Client.new(region: region) recording_files = body["payload"]["object"]["recording_files"] meeting_id = body["payload"]["object"]["id"] token = body["download_token"] path = recording_files[0]["download_url"] download_path = "#{path}?access_token=#{token}" object_key = "#{meeting_id}.mp4" logger.info(download_path) logger.info(token) URI.open(download_path) do |file| s3_client.put_object({ :bucket => bucket_name, :key => "recording/#{object_key}", :content_type => "movie/mp4", :body => file.read }) end end
Zoomの録画データをダウンロードする際には、ダウンロード用のトークンとURLを組み合わせる必要があります。 そのため下記のように新しい文字列を生成しています。
token = body["download_token"] path = recording_files[0]["download_url"] download_path = "#{path}?access_token=#{token}"
また、Lambdaの/tmpでは最大512MBしかファイルを保存できないので大規模な録画データの対応も考え、URI.openで受け取ったデータをそのままS3へと渡しています。
Zoomで保存されている録画データはMP4形式のファイルとなっていますので、MP4でS3に保存するよう指定しています。
URI.open(download_path) do |file| s3_client.put_object({ :bucket => bucket_name, :key => "recording/#{object_key}", :content_type => "movie/mp4", :body => file.read }) end
最後に、Lambdaで使用するメモリとタイムアウトまでの時間を変更します。
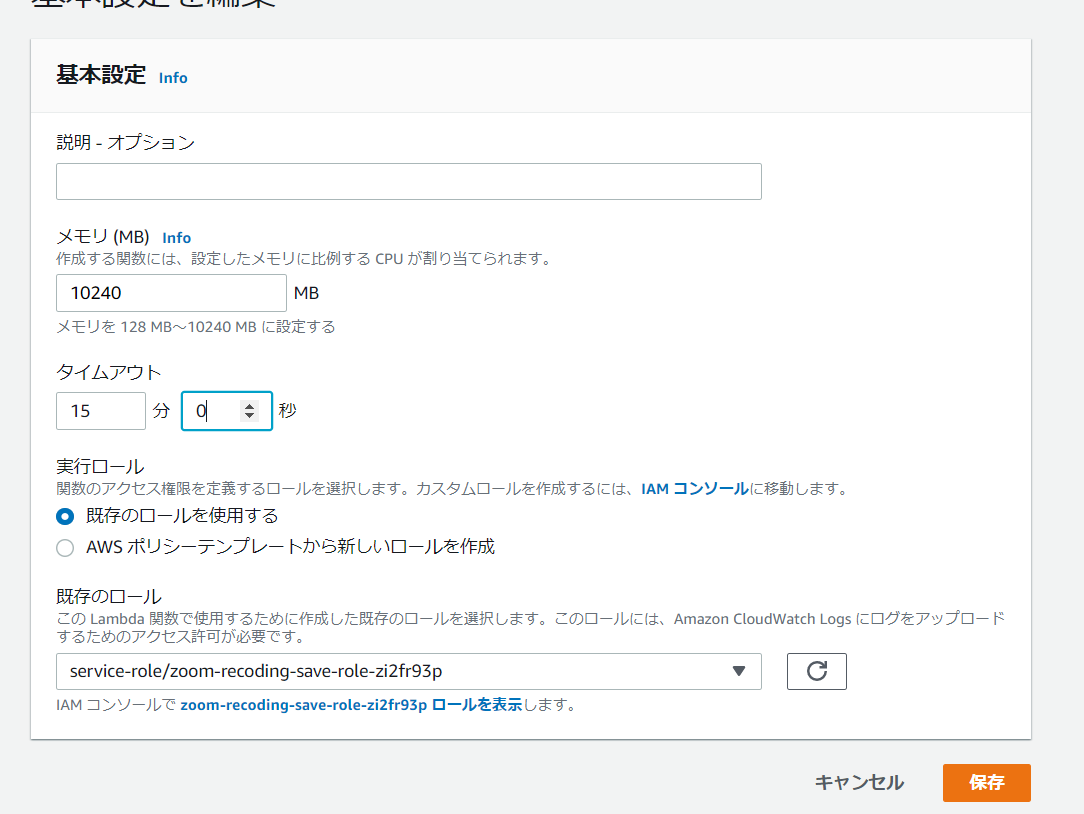
これでLambdaで録画データを保存する処理は完成です。
S3への書き込み権限をロールに追加
AWS IAMの管理画面を開き、Lambdaで関数を作成するときに生成したロールを選択します。
ロールにS3への書き込み権限を渡したいので「ポリシーをアタッチします」をクリックし、S3への書き込み権限を付与します。
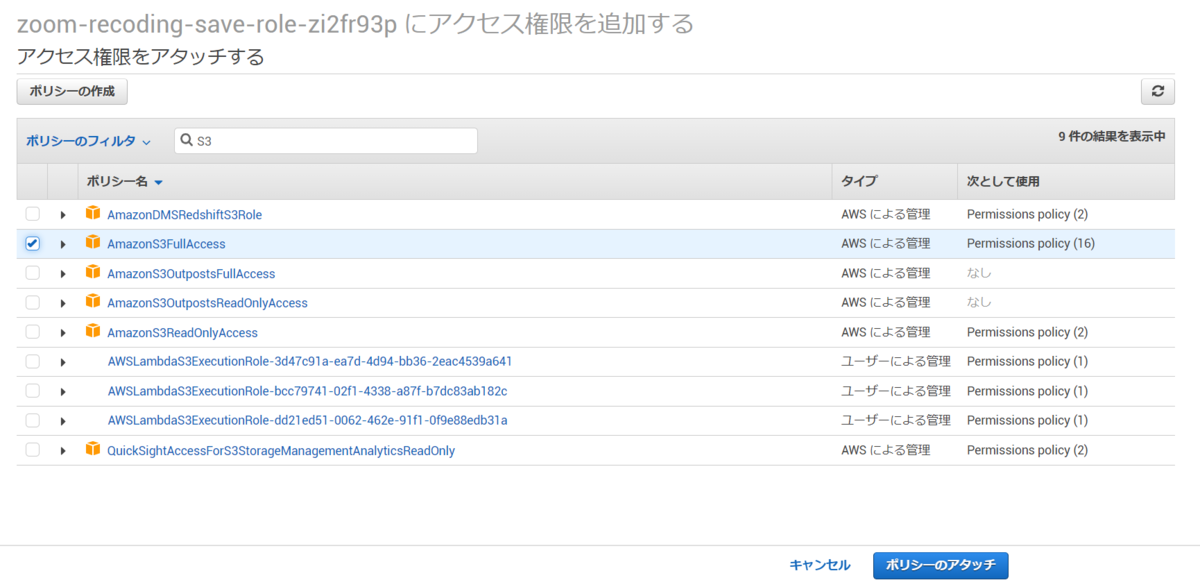
今回は動作していることが確認できればいいので、FullAccessを選択しています。 本来であれば、書き込みのみの権限にした方がいいと思います。
追加するポリシーをチェックした後、「ポリシーのアタッチ」をクリックし、権限を付与します。
API GatewayでWebhookを受け取れるようにする
次にAmazon API GatewayでWebhookを受け取る窓口を作成します。
API Gatewayの管理画面に移動し、「APIを作成」をクリックします。 以下のような画面が表示されます。
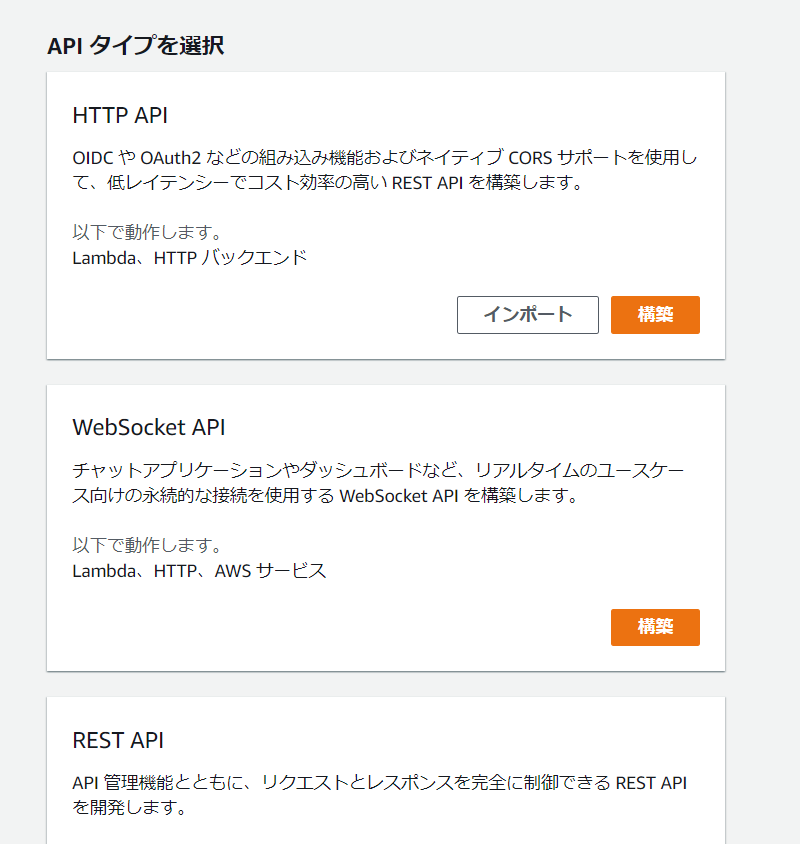
ここでは、「HTTP API」を使用します。「HTTP API」の枠内にある「構築」をクリックします。
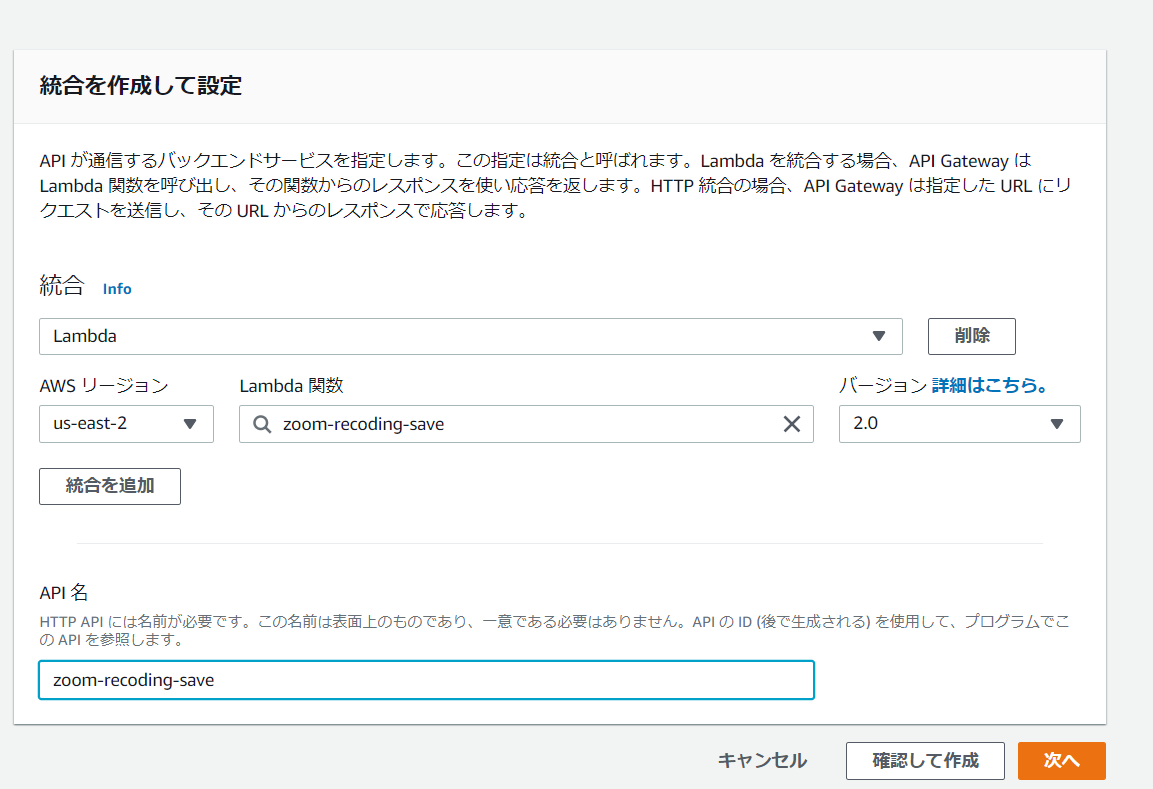
クリック後、上記の画面に遷移するので必要な設定を埋めていきます。
まずは「統合を追加」をクリックし、API Gatewayが使用するバックエンドサービスを選択します。 今回は、先ほど作成したLambda関数を指定しています。
また「API名」も入力する必要があるので任意の名前を入力してください。
諸々の設定を入力後、「確認して作成」をクリックします。
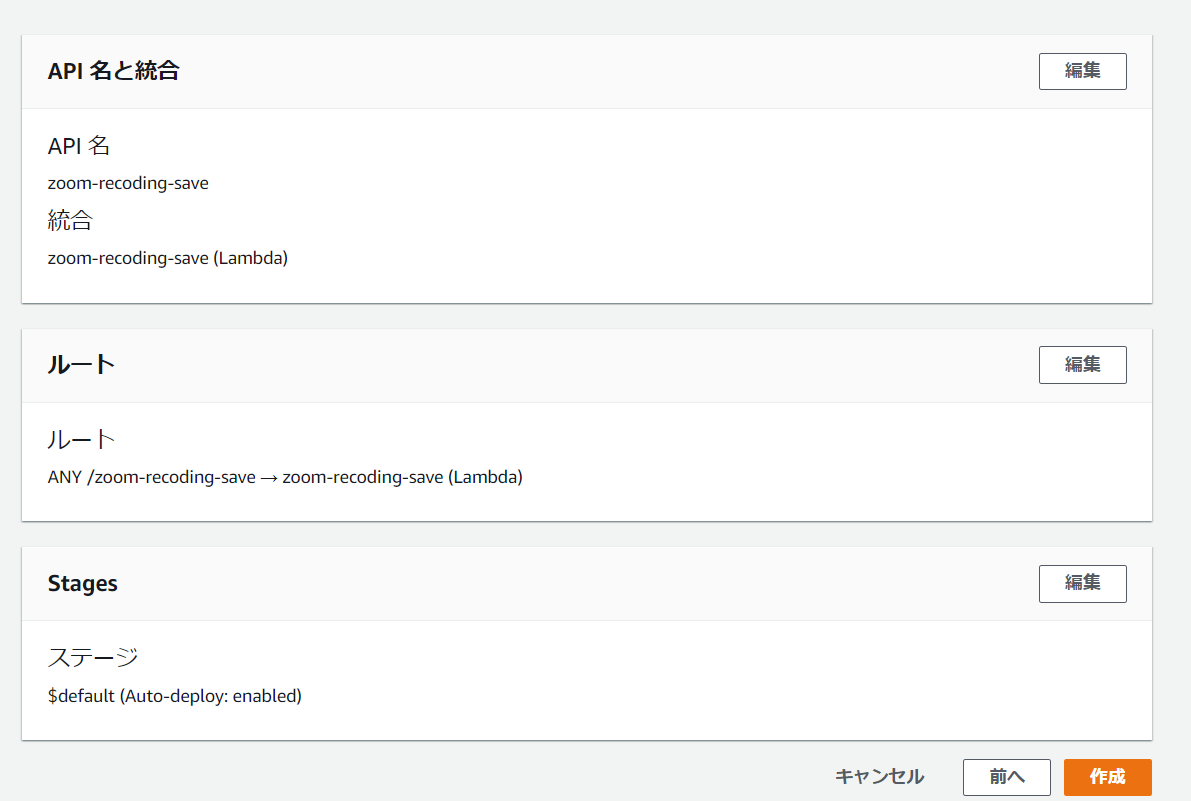
上記の画面に遷移します。 設定内容が正しいか確認したうえで「作成」をクリックします。
これでWebhookを受け取る窓口が作成できました。
ZoomでWebhookの送信先を指定
Zoomの開発者としてアカウントを設定後、https://marketplace.zoom.us/develop/createにアクセスします。
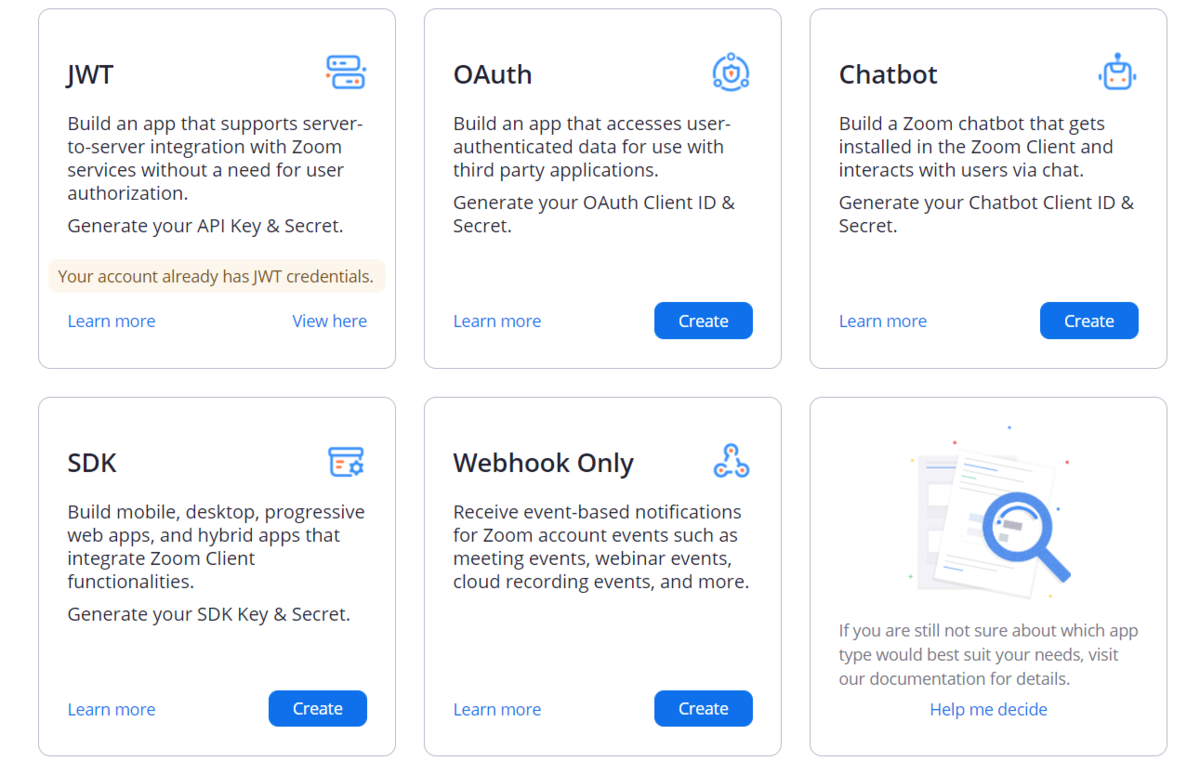
今回はWebhookが使えればいいので「Webhook Only」を選択し、新しくアプリを作成します。
アプリ作成後、以下の画面に遷移しますので赤枠の部分を埋めています。
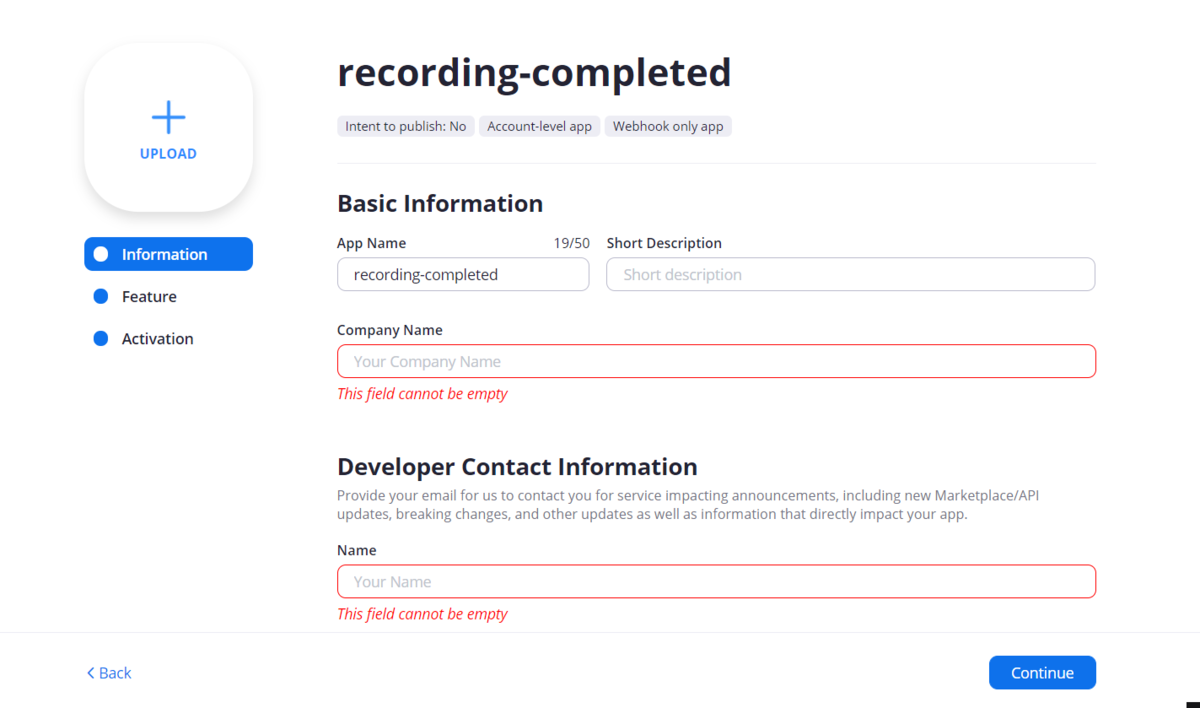
埋め終わったらページ下部の「Continue」をクリックします。
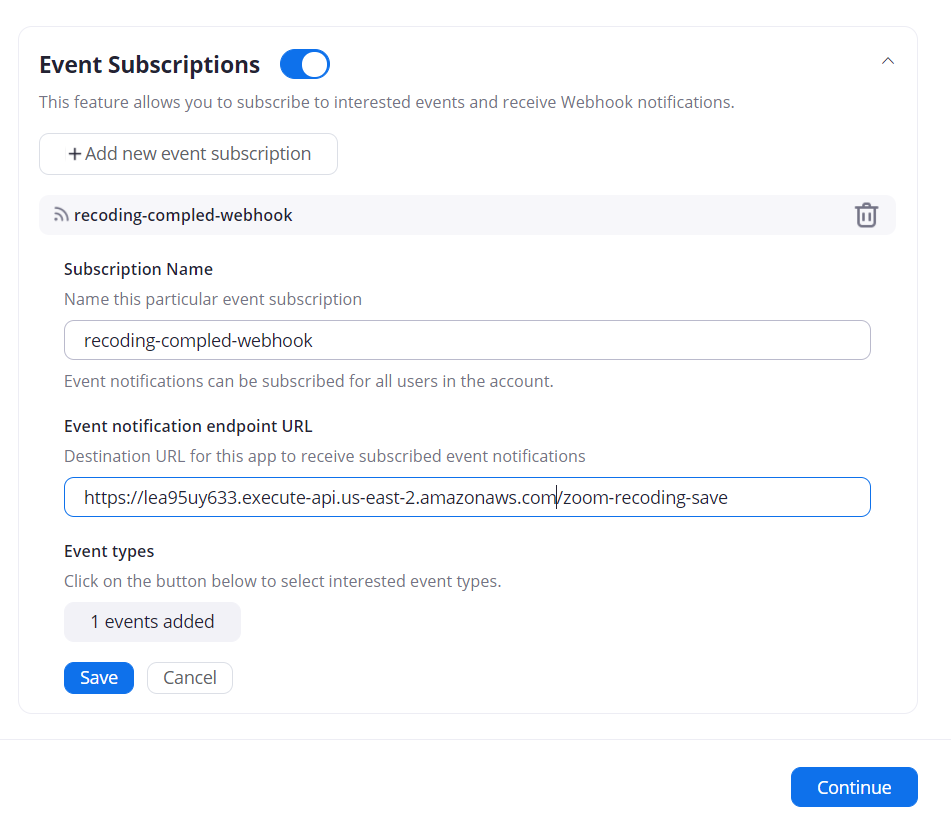
クリック後、上記の画面に遷移します。
「Event Subscriptions」を有効にし、「Subscription Name」に適当な名前を入力し、「Event notification endpoint URL」には先ほど作成したAPI Gatwayのルートを記入します。 また「Event types」には「All Recording have completed」を選択します。
最後に「Continue」をクリックし、アプリを作成します。
これでZoom側での設定は完了です。
S3にファイルがアップロードされたタイミングで文字起こしジョブを投げる
最後にS3にファイルをアップロードされたタイミングで文字起こしをするジョブをTranscribeへと投げる処理を作成していきます。
Lambdaで関数を作成する
ここでも再度Lambdaで関数を作成します。
関数名は任意の名前を付けてください。ランタイムは先ほどと同じようにRuby 2.7を使用します。
関数作成後、以下のようにジョブを投げるコードを書きましょう。
require 'json' require 'aws-sdk-transcribeservice' require 'logger' def lambda_handler(event:, context:) logger = Logger.new($stdout) logger.info("Hook Event") logger.info(event) record = event["Records"][0] s3 = record["s3"] region = record["awsRegion"] bucket = s3["bucket"]["name"] object_key = s3["object"]["key"] path = "https://#{bucket}.s3-#{region}.amazonaws.com/#{object_key}" job_name = "TranscriptionJobName_#{object_key.sub(/recording\//, "")}" output_key = object_key.sub(/recording/, "text").sub(/\.mp4/, "") logger.info("S3 info") logger.info(bucket) logger.info(object_key) logger.info(path) client = Aws::TranscribeService::Client.new(region: region) response = client.start_transcription_job({ transcription_job_name: job_name, language_code: "ja-JP", media_format: "mp4", media: { media_file_uri: path }, output_bucket_name: bucket, output_key: "#{output_key}.txt" }) logger.info("TranscriptionJob start #{response.transcription_job.transcription_job_name}") end
あとは、S3の/recordingディレクトリにファイルがアップロードされたタイミングでイベントを実行するように設定します。

「トリガーを追加」をクリックし、以下の画面に移動します。
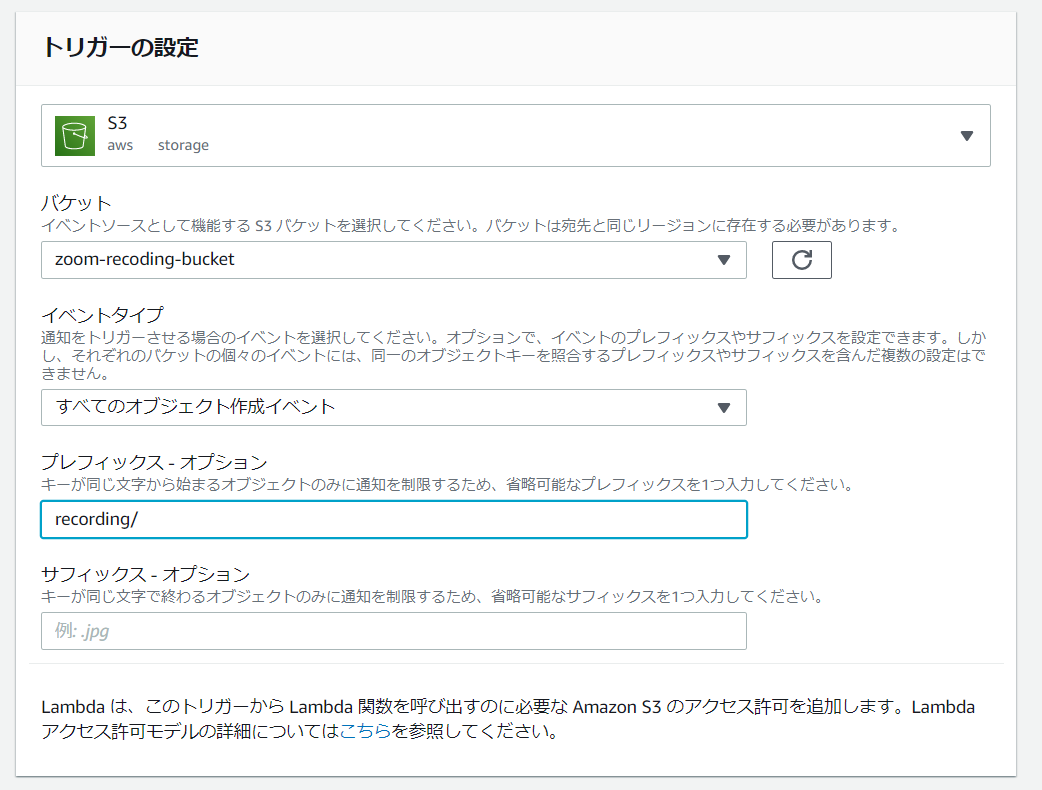
トリガーとなるイベントとバケット名などを入力していきます。
また、プレフィックスにrecording/を指定し、特定のディレクトリだけにアップロードされたイベントをフックしています。
最後に、今回作成した関数のロールに「AmazonTranscribeFullAccess」と「完全に削除」を追加します。 これはS3のファイルを読み取る&Transcribeへジョブを投げる権限を追加する必要があるためです。
おわりに
最終的に文字起こしで終わっていますが、ここからさらに録画データ内にNGワードがあった場合にSlackに通知するということもできそうです。